Python AWS Lambda Monorepo — Part 1: Project Setup

When going serverless, a micro-service monorepo can be a great way to structure your project. Why choose a monorepo instead of a monolith or a multirepo? Monorepos have the following benefits:
- Each Lambda function focuses on a particular task
- Sharing code across Lambda functions is easier
- Centralized deployment and documentation
- Scalable management of code using the same repository
In this series, we’ll learn how to build a simple serverless application (from setup to deployment) in AWS using a monorepo structure. We’ll go over the basics of the AWS services used but I encourage you to check out the official AWS documentation for in-depth information on each service.
Being the huge dinosaur fan that I am, our application will allow users to store dinosaur data, create hybrid dinosaurs and simulate hunts between a carnivore and herbivore! This is the serverless architectural diagram of the application:

Part 1 of the series will focus on setting up the project and services needed. In Part 2 we’ll learn how to create a custom Python package and use it across our different Lambda functions. Then in Part 3 we will test, build and deploy the code to the serverless environment. These are the services we’ll use to develop our application:
- AWS (Lambda, DynamoDB, IAM)
- GitHub
- CircleCi
For GitHub, we simply need to create our project repo. You can download the project on GitHub: https://github.com/bombillazo/python-lambda-monorepo

Hold on to your butts!
AWS
Amazon Web Services (AWS)is a cloud platform that provides users with computing resources and services. Users set up an account and pay as they use the services. These services allow users to develop and run applications without worrying about the underlying physical infrastructure.
Log in to the AWS Management Console to create our application infrastructure. It would be convenient to programmatically provision our infrastructure using a service like CloudFormation or Terraform but for the sake of simplicity (and learning), we’ll do it manually.
DynamoDB
DynamoDB is a NoSQL database, meaning it uses document data structures instead of traditional relational tables. One convenient thing about this is we don’t need to specify a data schema for our table before inserting data! We’ll use this service to store our dinosaurs here.
Start creating a new table in DynamoDB named dinosaurs with a primary key name being a String. Use the default settings for the rest of the table and create the table. Once created we should see the new table in our DynamoDB tables.


Lambda
Lambda is a serverless computing service that allows us to run code without needing to manage the underlying infrastructure. We’ll create 3 Lambda functions:
- create_dinosaur
- create_hybrid_dinosaur
- fight_dinosaurs
For each function, enter the Lambda function name, select Python 3.7 under Runtime and create the function. We’ll leave the Permissions to the default so AWS creates a new role with basic Lambda permissions per function.

Once created we’ll have 3 empty Lambda functions waiting for code to be uploaded to them:

The remaining step to configure our functions is to add an Environment variable to each of them. Select each function and in the Configuration section scroll to the Environment variables. Add a variable called PYTHONPATH with the value of ./packages. This will be used by the Python interpreter to locate the packages we install and use in our functions in Part 2.

IAM
Last but certainly not least we have the Identity and Access Management (IAM) service. By default, all new AWS resources have no access to other resources, even if they were created by the same user or they’re all in the same AWS account. This tightens security by requiring us to explicitly grant access to our resources. So how do we grant access? This is where IAM roles, policies and permissions come in.
A role is an IAM identity that an AWS service can assume when executing its functionality. A policy is an object that holds permission statements, usually in JSON form. A permission statement defines if the policy allows or denies access to the specified resources. Here is an example of the basic structure of a policy in JSON format:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject"
],
"Resource": "arn:aws:s3:::examplebucket/item-*"
}
]
}In the previous example, the permission statement is allowing the S3 actions PutObject and GetObject on S3 objects with the prefix item- inside the examplebucket (note the * used). Ideally, we’d want to be as specific as possible when specifying resources so we only give access to what the policy needs. This prevents granting unintended access if the policy is reused or if a future resource happens to match a permission statement in the policy.
Policies can have multiple permission statements. Roles can have multiple policies attached, and a policy can be attached to multiple roles. In the IAM service, we can create and modify roles and policies. For more details on IAM, read the AWS AIM Docs.
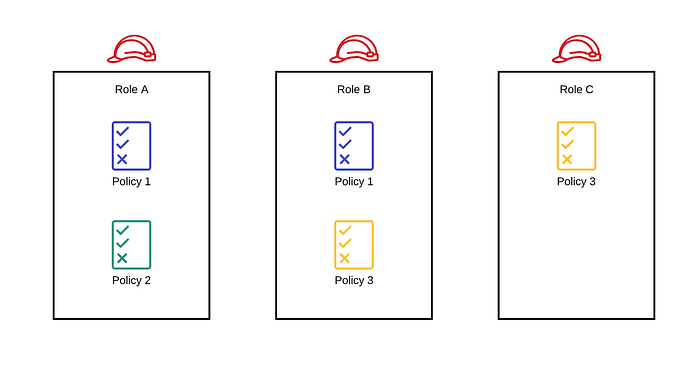
To give our new functions the permissions required to access DynamoDB, head to IAM and select Roles. We will see that there is a role for each Lambda function we created. These are the roles the Lambda function will assume when executing our code.

Select a function role and open up the policy in the Permissions tab to view the policy in JSON form. We’ll edit the policy by selecting Edit policy.

Select the JSON tab. Now we can edit the policy JSON. Inside the Statement array, add the corresponding Lambda function permissions that we want to grant (see below). Make sure to change the region and account values of the resource ARN to match your region and account number. After editing the JSON, Review the changes and Save the changes. Repeat the process for the rest of the Lambda functions.

create_dinosaur
{
"Effect": "Allow",
"Action": "dynamodb:PutItem",
"Resource": "arn:aws:dynamodb:region:account:table/dinosaurs"
},create_hybrid_dinosaur
{
"Effect": "Allow",
"Action": [
"dynamodb:PutItem",
"dynamodb:Query",
"dynamodb:Scan"
],
"Resource": "arn:aws:dynamodb:region:account:table/dinosaurs"
},fight_dinosaurs
{
"Effect": "Allow",
"Action": [
"dynamodb:Query",
"dynamodb:Scan"
],
"Resource": "arn:aws:dynamodb:region:account:table/dinosaurs"
},Now our Lambda functions will have the necessary permissions to do actions on our DynamoDB table!
The remaining setup steps in AWS relate to CircleCI. For CircleCI to upload our code to AWS Lambda, it requires both credentials to authenticate to our AWS account and permissions to execute the necessary actions of the deployment process. This is done by creating an IAM user with programmatic access and a policy with the required permissions.
To create the new IAM user, go to the Users section and select Add User. Give the user programmatic access only. We can use the prefix ci- to know it is for CircleCI. Complete the user creation process (we won’t make this user part of a group nor add tags for this example).

Once the user is created we’ll get an Access Key ID and a Secret Access Key for the user. These are AWS credentials so make sure to store these in a safe place like a password manager or encrypted local storage (if you do lose them, go to the Security Credentials tab in the user, delete the lost access key and create a new access key). These credentials will be used in the next section when we set up CircleCI.

Now that the user is created, we create a new policy. This new policy will grant permission to upload code to our lambda functions. Go to the Policies section and select Create Policy. We will name this policy circleci_policy. Using the JSON editor, we will allow the lambda:UpdateFunctionCode action on all lambda functions:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "lambda",
"Effect": "Allow",
"Action": "lambda:UpdateFunctionCode",
"Resource": [
"arn:aws:lambda:us-east-1:*:function:*"
]
}
]
}Finally, we will attach the policy to the CircleCI user. Go to the CircleCI user and select Add Permissions under the Permissions tab. Select the option to attach an existing policy directly and search for our circleci_policy. Select the policy and complete the process.

Now we’re finished with AWS! Let’s move on to setting up CircleCI!
CircleCI
CircleCI is a continuous integration platform that allows us to automate the deployment of our project to the live environment. CircleCI works by connecting to our GitHub account and allowing us to add our project repositories to CircleCI. Our project will have a .circleci/config.yml file that contains the deployment configuration of our project. When all is set up, CircleCI will detect code pushes to the repo and will automatically run jobs defined in the config.yml. These jobs execute in containers running in the CircleCI service platform. The config.yml file specifies the details of what environment, docker images, and dependencies to use for our jobs as well as defining the steps and logic for the testing, building, and deployment of our project. We’ll see all this in Part 3 of the series.
Once our account and project repo is set up in GitHub, we create an account in CircleCI and link our GitHub account. When done we’ll be able to see our projects in the Add Projects section.

Select Set Up Project for the repo containing our dinosaur monorepo project. We’ll select Linux for running our jobs, and select Python for our project language. We’ll configure the config.yml file in our project in Part 3.

Now we will use the credentials we set up in AWS earlier for our CircleCI user. Go to the project settings (click on the gear icon next to the project name in the Jobs view). Navigate to the Environment Variables section. We will add two variables: AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY. Paste the corresponding key-value into each variable and save the changes. What we have just done is store our IAM CircleCI user credentials in our CircleCI environment variables, which will be accessible in our deployment script. We’ll see the details in Part 3.

Wow! We have our whole project setup and our services integrated! Now we can focus on our application itself. To learn more about infrastructure setup, I challenge you to create the Lambda functions or the DynamoDB table using AWS CloudFormation.
In Part 2, we will look at how to create custom Python packages and share them across our Lambda functions. Stay tuned!
